この記事はPrivacy and secrecy: a general analysisを翻訳したものです。
さて、私は自身の2回目の投稿として、特定のプロジェクトの概要ではなく、別の何かについてに投稿することに決めました。私がとても重要視しているPrivacyとSecrecyというコンセプトの概要についてより概念的側面を説明し、またそれがゼロ知識証明、ZKSNARKs、Trusted Execution Environments(TEE)、Multi-party computation(MPC)などの様々な用語がより一般的になってきていることにどのように関連しているのかを記事にしていきたいと思います(本記事の最後に余裕があれば、準同型暗号や、区別不可能性難読化などのより特殊なシステムについて少し説明を加えるかもしれません。しかし私はその知識は役立つというよりも混乱を招くのではとも考えています)。本プロジェクトの骨子に入る前に、私は特に本記事はそれを推進している人々の中の一人の要望に応じる形で書いたものであり、記事に対して特定のプロジェクトの名前をつけないことにすると言っておきたく思います。また本記事はEnigmaとKeep両方のプロジェクトの代表者が技術的な正確さを保持していることを前提に読むようになっていることに注意してください。そして潜在的な利益相反を明確にしておくため、いずれの当事者による内容変更の箇所も明確化します。
アウトライン:
パートI:定義:
PrivacyとSecrecyに関わる個々の技術の話をする前に、まずは「Privacy」と「Secrecy」という用語の定義、またデータ、トランザクション、コンピューターのPrivacyやSecrecyとの区別、そしてセキュリティプロパティの保存と作成との違いを明確にするために少し時間を取ります。関連する用語の意味を誰もが知っていると主張する人はなかにはいるかもしれません。ではなぜ定義を確立する必要があるのでしょうか?それには大きく2つの理由があります。まず最初におそらくこれらすべての用語の定義は少しずつ異なっている点です。定義を確立することに時間を割くことで、その使用法や意味についての議論が最小限に抑えられると考えています。次に、正式な主張をするために、私たちが探している属性について正確なアイデアを持つ必要があります。あまりにも多くの暗号スキーマが略式を軽視し、曖昧になり、失われつつあります。
定義I:Privacyとは目に見えるものではありますが、特定の情報なしでは判読できないものです。
言い換えれば、プライベートな情報は私たちが暗号化について考えているときに一般的に思い浮かべることです。つまり私たちはあるメッセージが送信されていることを知り(極端な場合、「はい」または「いいえ」というメッセージなどほんの少しだけの情報を持つメッセージでも)、正確な暗号文(暗号化されたメッセージ)を取り出すことができますが、実際のメッセージは読み取れません。署名の場合、署名されるそのメッセージが何であるかを正確に知っていますが、鍵なしで署名を再構成することはできません。まとめると、明らかに封をした封筒内のメッセージのような非公開のものを想像してみてください。あなたはどこにそれがあるのかを正確に知っていますが、読むことはできません。より正式に言えば、プライベートなメッセージはその場所や形状を知っていても、他のメッセージとは区別できないものです。対照的にSecrecyとはメッセージの場所さえも難読化します。プライベートなデータも同様です。
定義II:Secrecyとは他の通信手段からも検出されたり、区別されないものです。
言い換えれば、封をした封筒ではなく、Secrecyとは目には見えないインクによるメッセージに似ています。読むことができないだけでなく、気付くことさえもできません。これは暗号化ではなく、ステガノグラフィーとして古くから知られている領域です。Secrecyのメッセージは多くの場合、プライベートメッセージよりも安全性が高くもなり、また低くもなります。頻繁には検出されないため、侵入することはより難しいのですが、もし送信方法が検出された場合、保護できないことがあります。まとめると、折りたたまれて隠された封をしたメッセージを想像してみてください。それは見ることは難しいですが、一度見ることができれば読むことは難しくはないのです。より正式には、Secrecyのメッセージはそのようなメッセージを含む送信がそれを含まない送信と外見上は同等なものです。一方でSecrecyのデータとは分散システム上の場所や単一のマシン内の場所がわからないデータです。
定義III、IV、およびV:データとはシステムに含まれる情報のことを指します。コンピュテーション(計算)とはあるデータとその結果について実行されるオペレーション、特にそのデータに関する情報が漏洩しているかどうかを指します。トランザクションとはファイナンシャルまたはその他の取引のことを指します。
データのPrivacy:データの所在を確認することはできるが見ることができないこと
データのSecrecy:データの所在を確認することができないこと
計算のPrivacy:計算はシステムのデータに関する情報を漏えいせず、その結果も秘匿すること
計算のSecrecy:計算が検出、もしくはどのコンピューターが計算を実行しているかは未知であり検出不可能であること
取引のPrivacy:特定の取引の金額や受領額などの内容が読めないこと
取引のSecrecy:ネットワークの前後をチェックできても、個々の取引を検出できないこと
定義VIとVII:プロパティ(属性)の保存とは既定のオペレーションがシステムにプロパティを失わせないことを意味し、プロパティの作成とは以前は持っていなかったシステムにプロパティを追加することを意味します。
例えば、共通鍵暗号はシステムのデータPrivacyのプロパティを作成し、暗号署名はそのシステムのデータPrivacyの特性を保存します。
パートII:ZKPs(ゼロ知識証明):Privacy保護メカニズム
関連用語の定義を確立したので、3つの技術の1つ目であるゼロ知識証明の分析へと進みましょう。この暗号技術が可能とするのはデータに関することを何も公開することなく、データに特定のプロパティがあることを証明することです。特にゼロ知識の証明は任意のランダム性をコントロールでき、そのデータがプロパティを持つ状況下において、そのデータについて何も知らない人によってモデル化されなければなりません。さて、これはかなり無味乾燥とした公式な用語ですので、私はそれを例えを使用して説明した方がよいと思います。(この例えはBoaz Barak氏とCS 127の素晴らしいクラスのおかげです)。あなたは2つの入り口がある大きな洞窟の前に立っていると想像してください。あなたは2つの入口の間には通路があることを知っており、外にいる友人はあなたがそれがどこなのかを知っているということを確信しています。しかしあなたはこの通路をすべて自分だけのものとして使用したく、特にあなたの友人が他の人にそれを教えるようなことは避けたく、またあなたの証拠を使って他の人への通路の存在を証明することもしてほしくないと思っています。あなたはその情報を明らかにせずに通路があることをどのように証明することができるのでしょう?
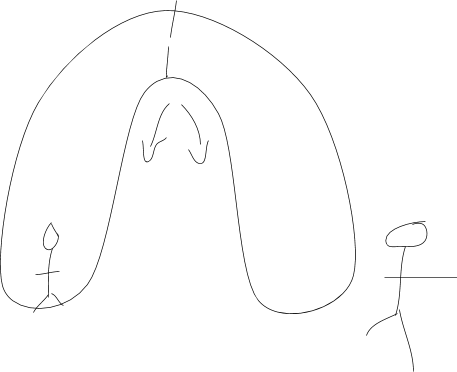
ゼロ知識証明の洞窟
その答えはランダム化です。あなたが洞窟に入り、あなたの友人にあなたには見えないようにコイントスをするように指示し、毎回コイントスした表・裏の結果によって決まった洞窟の出口から出てきます。これは通路がある場合のみ一貫して可能となりますが、第3者にとってはあなたの友人とあなたがこのランダム性を計画されたものと思うかもしれません(シミュレーションパラダイムの下で、シミュレーターはコイントスによって決定された入口にあなたが偶然に入って行った捉えます)。より一般的には、現実世界ではゼロ知識(インタラクティブ)証明はこのようなものに見えます(実際にはこれは一般化されたゼロ知識証明のプロトコルですが、その違いは無関係というには不十分なくらいわからないものです)。
あなたは検証者VにプロパティAを持つデータDを証明したいと思い、次の手順を実行します。
- 暗号化、ハッシュ化、もしくは文字列Sを持ついくつかのセットを提供します。
- Vはコイントスします。
- Vが表を出したのであれば、Sが実際にDにコミットしていることを検証するために、Vはあなたに文字列を平文にするよう求めます。
- Vが裏をだしたのであれば、SがプロパティAを持っていることを検証するために、Vはあなたに文字列を平文にするように求めます。
Sは固定されているため、Dが実際にプロパティAを持っていることが、確実に一貫してこのテストをクリアできる唯一の方法なのです。つまり、このテストに一貫して成功することはDがAを持っているという証明になるのです。しかしあなたはDに容易に再変換できない文字列を公開している、もしくはD自体を公開しているため、この証明はDについての追加情報を出さないようになっているのです(ここでゼロ知識を確立するために微妙な差異はあります。より多くの情報を希望する人はハミルトン路のゼロ知識プロトコルを調べるように求められます。ここでの事例の特定の事項はそれに基づいています)。
よって私たちはゼロ知識証明のその目的を持っているのです。それは既に述べた用語において述べていますが、おわかりでしょうか?セクション見出しで説明したように、ゼロ知識証明はデータのPrivacyを保護しながら、そのデータの特定の選択されたプロパティを公開します。言い換えれば、例えば生年月日などのいくつかのデータを持っている場合、実際の年齢を公開することなく、選挙権があることや飲酒できる年齢であることを証明することができます。同様にあなたの信用スコアをその計算のために使用されたデータのいずれかも公開することなく、信用スコアがある特定の値であると証明することができます。さらにゼロ知識証明は当事者同士があるトランザクションを金額、トランザクションの時間、受取人アドレスを公開せずに有効であり、かつ2重支払になっていないことを検証することができる計算のPrivacyを可能とします。これはもちろん非常に有効です。しかしそれはデータのPrivacyを作り上げるための完全な方法ではなく、あるいは実際に計算のPrivacyを作るための完全な方法でもありません。理由はおわかりでしょうか?(ヒント:前パラグラフの修飾語句に注目してください)
少し考える時間を与えます。
...
もう少しだけ追加で与えます。
...
それはゼロ知識証明とは計算を実行している時にあなたが既に持っているデータのPrivacyだけを保護できるためです。つまり、データを他の人に送信する必要がある場合や、大量のデータを照合して計算を行う必要がある場合、セキュリティホールが発生してしまいます。もちろん最終的な計算を実行している人は自分のデータを漏えいすることなく結果の正しさを証明することができます。しかしその時点で、彼らはあなたのデータを持っているので、それを使用して何でもできてしまうのです。したがってゼロ知識証明は一般化された計算のPrivacyの問題を単一ノードの計算のPrivacyの1つに変換し、実際にはセキュリティの脆弱性を集中化させます。部分的な解決策ではあるのですが、完璧な解決策ではないのです。(ゼロ知識証明は次のいくつかのセクションでも役割を果たしています。それには目をつぶってください!)
パートIIb:SNARKsとSTARKs:なぜ、まず最初に「検証者」が必要なのでしょうか?
さてゼロ知識証明は隔離された状態でのPrivacyの保護という点では優れていますが、現実の世界では上記で述べたようにそれらを使用することに関して問題点がいくつかあります。まず、上記で説明したプロトコル(これもまたハミルトングラフのカバーをベースにしています)は長く、それにはあなたが望むプロパティとブール充足可能性問題に対する状態のトランザクションを必要とし、そのトランザクションをグラフに変換し、そして最後に大規模グラフをベースとしたゼロ知識証明となります。2番目にプロトコルはインタラクティブなものです。つまり証明を行いたい場合、ランダム性を提供するためにネットワーク上に検証者を必要とします。この両方ともに私たちが作成準備システムにおいて望んでいる以上にゼロ知識証明の待ち時間を増加させます。これらの問題をZero Knowledge Succinct Noninteractive Argument for Knowledge(ZKSNARK)を作成することで解決することができるでしょうか?
サイズ:多項式補間(n次多項式でn + 1を知っていれば、それをリカバーすることができるという事実)とRSAが暗号文の掛け算を保存しているという事実を使用したかなり巧妙なトリックを使って、あなたは非常に短いZKの平方根の証明を有する多項式(二次スパンプログラミングとして知られているNP完全法での)としての機能をあなたのプロパティにエンコードすることができます。(この説明はかなり難しいですが、https://blog.ethereum.org/2016/12/05/zksnarks-in-a-nutshell/でわかりやすく説明しています)。
インタラクティビティ:証明をノンインタラクティブにする方法はいくつかあります。もしランダム性を保持したい場合、検証者によって提供するのではなく、外部の証明者にそのランダム性を持たせることができます(一般的には外部情報のハッシュとコミットされた証明文字列を使用します)。そして検証者はプロビジョニングがランダム性と一致するかどうかをチェックするだけで、証明者とコミュニケーションする必要はありません。あるいは少数のランダムノイズを多項式に加え、ランダムと区別できないすべての非プロパティ情報(特に、誰かがあなたの証明を再構成するために必要な証拠)を作成することで、ゼロ知識証明を行うことができます。繰り返しますが、これは少し数学的になってしまい申し訳ございませんが、上記のリンクから詳細を確認して頂ければと思います。
SNARKとは対照的にSTARKはノンインタラクティブ性を保持するだけでなく、多項式と確率的に検証可能な証明技術に関するインタラクティブな証明のための新しいアルゴリズムのブレンドを使用し、検証者の検証に関わる時間を大幅に削減し、大きな定数係数によって証明の複雑さを減らします。サイズとスピードによる待ち時間の問題点を解決し、外部のランダム性要件を完全に排除します。またここで私は大事な部分の説明を省略しました。ええ、それは直観的なアイデアの発想のためになるすべての数学的なことです。技術的な詳細が必要な場合は、Eli Ben氏のセッションのオリジナル論文(https://eprint.iacr.org/2018/046)をご確認ください。
これらの手法はいずれもZK証明の待ち時間や複雑さの問題を解決しますが、セキュリティ上の問題は解決しません。マルチノードコンピュテーションは以前と同じようにシングルノードの悪意に対して同じように脆弱なままなのです。
パートⅢ:HSMsとTEEs:見たところまだPrivacyの保護しています:何が変わったのでしょうか?
ゼロ知識証明ではマルチノードのデータと計算のPrivacyの問題が単一ノードへと縮小したような世界に突入しました。しかし、この時点では、私たちは行き詰ったように見えるかもしれません。単一ノードのPrivacy問題を解決する方法はないように思えます。結局のところ正しいコードがデータ上で実行されているだけでなく、そのコードがデータを把握していること、そしてその他に何もないことを知る方法が必要となってきます。そうでなければ、常にリークしてしまうリスクに晒されている状態となっています。しかし目標達成は不可能であると思われ、私たちはデバイス上で実行されているプロセスと物理的なアクセスの知識を全て持っている必要があるのです。
ここで私がこのように言ったので、おそらく人によっては疑問を持たれているかもしれません。物理的な改ざん防止機能があるデバイスを作ることができないのでしょうか?もちろんこの種の取り組みは行われています。ハードウェアセキュリティモジュールのコンセプト(HSM)はまさにそれなのです。例えば一部のスマートカードで見つけることができるこれらのデバイスはほぼ完璧な改ざん防止機能を備えた非常に特定されたコード(一般的にはデバイス上に格納されたキーまたは同等のシンプル性かつ高セキュリティコンピュテーションによる暗号化もしくは暗号解読オペレーション)を実行するように構築されており、その両方ともに物理的およびソフトウェア攻撃の両方に対応しています。これらのデバイスの中でも最も安全ものは構成部品の故障を引き起こす温度や電圧の変化などの環境的な攻撃にも耐えられるように構築されているものです。(私が知っている限り、攻撃後のシステムインテグリティの保護という点においては、攻撃に対して安全な対抗策はありません。例えば、システム全体を液体窒素中で凍結させることはもしシステムの再構築を行わない前提の場合、後で読み取るのに十分なメモリの状態を保持するということに関しては比較的有効な方法です)。これらの種類のシステムでは単一のノードでさえ鍵自体を秘密に保持ような方法で暗号化と暗号解読を行うことができるという点において確かに大きな進歩と言えます。
ただし修飾子に注意してください。これらのシステムは具体的には暗号化と暗号解読のために機能しており、汎用コンピューティングではHSM上で実行するには複雑すぎます。その代わりに特定のコードだけが実行されていることを証明したり、検証できる条件を決める環境を整える必要があります。またその大部分のマシンは処理しているデータにアクセスできないことを認識しておく必要があります。言い換えれば信頼できる実行環境(TEE)が必要なのです。私が知っているTEEプロジェクトの中で最も普及しているものは信頼できる処理をサポートしているIntel CPUの特定のセグメントであるIntel SGXです。これらのTEEは前述のように2つの機能を果たしています。
1)あるデータ上で実行されることになっているコードが実際に実行されたことを証明すること(システム状態のハッシュと他のいくつかの小さなピースを比較することによって行われます。そのシステムのアーキテクチャーについてはhttps://eprint.iacr.org/2016/086.pdfをご参照してください)、
2)メモリを分離し、特権的なセグメントにて保持することによって、またユニットの起動時、シャットダウン時、およびCPU障害時に特定の手順に従い、その他のコードがそのデータへのアクセス権を持たせないこと。(再度になりますが、https://eprint.iacr.org/2016/086.pdfをご参照してください)。
これらが両方とも完全だった場合、私たちはデータPrivacy保護コンピュテーションスキーマを持つことになります。暗号化されたデータとあなたが希望しているコンピュテーションが格納されたキーによってそのデータを解読する指示を格納しているTEEに送り、そしてコンピュテーションを実行し、再解読して結果を返信します。もしあなたがシステムがあるデータ上で実行される特定のコードによって設定されている状況での一般的な目的に興味があれば、TEE内のコードが「入力1にコンパイルし、入力2で実行」というような状況を考えてみてください。これは特定のアルゴリズムよりも信頼できる証明を一般的に信頼できる環境へもたらします(解読/再暗号化戦略を念頭に置くだけでなく、この戦略も念頭に置いてください。もし準同型暗号をカバーするのであれば、有効となります)。
さて、私の文書のスタイルに慣れた人なら誰でも次に書かれていることを予想できるでしょう。残念ながらこれら2つのは(まだ)完璧とは言えないのです。公平であるために言うと、SGXのコード部分を修正するための証明は適切であると思われる研究結果からわかるように、侵入されていないように思われます。言い換えれば、あなたのTEEがプログラムXをあなたのデータで実行したと言ったとした場合、それはほぼ確実に真実を伝えていることになります。しかしPrivacyの保証は不完全です。TEEがマシンを使い果たし、そのマシンとある程度メモリを共有しているという事実は多くのキャッシュレベルおよびプロセッサーレベルの攻撃を可能にし、外部マシンのユーザはメモリ内の様々な値を設定し、 情報を抽出するためにTEEが引き出し使用する情報を追跡します(理論的には開発者はこれらの種類の攻撃に耐性のある内部コードを書くことができるはずです。ただ実際には非常に困難なのです。https://cdn2.hubspot.net/hubfs/1761386/security-of-intelsgx-key-protection-data-privacy-apps.pdfを参照してください。)しかしこれらの攻撃は実行するには多少コストがかかりすぎることがよくあります。
パフォーマンス面ではTEEとHSMは通常のクラウドコンピューティングよりも理論上は追加の情報や計算上の複雑さを必要としませんが、実際にはアルゴリズムが速度よりも最適化を重視した場合、わずかに速度が低下することがあります。
つまりTEEは完璧なものであり、データに対するPrivacyを保持する高速汎用コンピューティングスキーマを提供しますが、サイドチャネルを通じて情報を引き出すことができるTEE内では少し欠陥も存在します。 対照的にHSMは同じ欠陥はありませんが、アプリケーションにおいてはより制限されています。
パートIV:MPC:Privacyの保護とSecrecyの作成:なぜ複数のパーティーが存在することが問題になるのでしょうか?
さて、私たちはゼロ知識証明とTEEをざっと見てきました。どちらも安全かつ様々な範囲においてPrivacy保護がされていましたが、両方とも攻撃者が情報を抽出できる既知のロケーションにおいてのクリアテキストデータに起因する欠陥には被害を受けておりました。現時点では本当の意味でのプライバシー保護は不可能であると考えるのは許されているかもしれません。結局のところ、脆弱性なく全く暗号化されていないデータ上で操作できない場合、何ができるのでしょうか?
もちろんその答えは決して暗号化されていないデータを組み合わせることではありません。 したがって私たちはコンピュテーションを保護するプライバシーの暗号スキーマの次の段階へと導かれていきます。それがマルチパーティーコンピュテーションです。スキーマとしてのMPCは2つのピースが存在しています。1)シンプルなピース:秘密を安全に分割すること。 2)複雑なピース:分割された秘密でどのように動作するかということ。私たちはこれらのピースを一つずつ順番にカバーしていきます。
まず、秘密を多くのパーティー(当事者)に非公開で分割する方法を考えてみましょう。もちろん秘密の部分をそれぞれに与えていくという単純なアプローチもあります。しかしそれは完全には非公開にはなりません。それぞれのパーティーは秘密についていくつかの情報を持つことになり、持っている情報を持ち寄りより多くの情報を得ることができます。これは明らかに擁護できるものではありません。十分な数のパーティーが集まっても完全に読み取れないようにならない限り、秘密は安全である状態を望みます。すべてのパーティーが一斉に集まり秘密を再構築するというシンプルなケースを考えてみましょう。この場合、秘密を何らかの正数または負数としてエンコードすると、非常に簡単なアルゴリズムが得られます。N数のパーティーでは、1つを除く全てにn-1個の乱数を与え、最後の人にその数値を与えます。n-1の合計にその数値が加えられた時、秘密全体となります。数値は正または負の値を取ることができるので、n個の値のうちn-1個であっても、N番目の数値が得られるまで秘密が何であるかはわらかないようになっています。
それにより私たちはN個の秘密を共有にしていることになります。重複性のために秘密をN以下で再構築できるような秘密の共有を行うにはどうすればいいでしょうか(つまりノードがグリッドから外れても秘密を再構築できるということ)。その答えは多項式補間と呼ばれるものにあります。例えば2つの点が直線をどのように定義するのかを覚えておいてください。また1つの点から可能となる直線は無限にあります。より多くの点を使用すると、より複雑な曲線/多項式を定義することができます。曲線の複雑さ/程度によって完全に確定するために必要な点の数が決まります。したがって私たちの秘密共有スキームは次のように実行されます。5人のなかで秘密Sを共有し、2人がそれを再現できるようにしたいとします。Sを数字としてエンコードし、y軸でSと交差するランダムな線を作成します(どの2点においてもSを再現させため)。次に線上の1点をそれぞれの人に送信します。2人が点を共有している限り、その2人はオリジナルのラインとその秘密を引き出すことができますが、1つの点ではそのラインの可能性は無限に存在することになります。
そう、それにより秘密の共有ができるのです。データを再構築せず、プライバシーを損なわずに、どのようにこの共有データ上で運用できるのでしょうか?もしそれを考えるのであれば、加算や乗算から演算を得ることができます(あなたが数値を様々なデータ形式にエンコードやデコードできることを前提としています)。 そのため、加算と乗算がこのスキームで可能であると見せるだけでいいのです。加算と定数の乗算は簡単で、それぞれの人が自分の点を加算もしくは乗算するだけです。しかし2つのシェアの乗算は若干困難です。それぞれの人が自分のシェアを単純に乗算すれば、2倍の次数の多項式上においての点となり、それによりデータを公開するためや決定するための点は2倍以上となるのです。
この次数削減のステップではもしネットワーク上で派生した点を再共有する必要がある場合、MPCに多くのコミュニケーションの複雑性が加わることになります。(加算を使ってすべてを行うことがなぜできないのだろうかと疑問に思っている人は遠回しな言い方ではありますが、乗算を行うために加算を使うことはセカンドファクターが公開されていることに注意してください)。もしあなたが単純なMPCアルゴリズムの2次的性質について議論している人々を発見した場合、その次数削減がどこから来ているのかがポイントとなります。同様にMPCを高速化する最新のアルゴリズムはすべてこの乗算ステップを取り除くことを当てにしています。
まず、私たちは巧みな代数を使って1ステップの乗算を可能にするための同意された定数を共有するSPDZを保持しています。しかしこれらの定数を送信するための通信時間がかかってしまうのです(https://bristolcrypto.blogspot.com/2016/10/what-is-spdz-part-2-circuit-evaluation.htmlにて説明します)。次にクォーラムベースのプロトコルを使用しています。これらのプロトコルは一度にデータを計算し、結果をより多くのコンピュテーションに集約し、個々の乗算のコストを削減しています(小規模なネットワークで実行されるため)。これらのプロトコルはより速いのですが、秘密を新しいパーティーに比較的頻繁に再共有することが必要であり、それが新たなコンピュテーショナルコストを発生させます(再共有の頻度についてのより詳細な情報についてはhttps://www.boazbarak.org/cs127/Projects/mpc.pdfの第2章をご参照ください)。またMPCの場合に正当性の証明を提供するために、これらのスキームは一般的にインプットにおいて実行されたコードが正しい結果を作成するゼロ知識証明においてすべてのパーティーが証明する検証ステップのフォームを組み込みます。それが追加のシャットダウンを引き起こします(ある特定のプロトコルは常習的な不正行為者が捕まえられるという前提で、パーティーのランダムなサブセットの入力と出力を通じた事後追跡に依存しています)。だからMPCは前の2つの方法よりも明らかに遅いのです。
しかしこのスキーマが私たちに提供するものに注意をしてください。大規模なプライベートコンピュテーションに対して十分なパーティが正直であると仮定します。 MPCは計算された後でもデータのPrivacyを保証する機能を提供しています。さて、このスキーマでさえも不完全であることに注意してください。不正を犯すKを含むN数のパーティーの間でデータを共有すると、彼らは秘密を再構築することができます。これらのパーティーから彼らが同じ秘密を共有していることを隠すことは可能であると考えるかもしれませんが(おそらくプロトコルのすべてのコンピュテーションを匿名化することによって)、そのような秘密のMPCは不可能です。これの証明は少し関わってきますが、要するに敵対者同士が互いを認識するのに十分な情報を交換することは常に可能であることがわかっているのです。(この結果といくつかの推論の詳細についてはhttps://www.boazbarak.org/cs127/Projects/mpc.pdfのパートIを参照してください)。
要約すると、MPCはスピードを犠牲にして、(ほぼ)完全に一般化されたPrivacyが保護されたコンピュテーションを提供しています。MPCシステムではデータを平文で保持する必要なく、一般的なコンピューティングのすべての機能を利用できます。
パートV:結論:
そこのあなたが現在考えていることを推測してみましょう。「たくさんの情報がありました。システムの基本的なこと以外にここから抜け出せなければならない簡潔な学べたことがあったのでしょうか?」えぇ、システムの基本的なことは重要ですが、実際に2つのことがあったと思います。第一にセキュリティ上の問題を明確にしています。定義を明確にすることなく、またデータと取引のPrivacyを区別することをしなければ、ZKP、TEE、MPCの間の違いを明確にするのは簡単ではありませんでした。
次に、より重要なのは特効薬はないということです。しつこいようですが、それを繰り返すことをお許しください。特効薬はありません。完全にPrivacyの問題を解決する答えや技術はないのです。ZKPのように部分的な答えを提供するものもあります。他のものはTEEとMPCの比較に見られたように、セキュリティを犠牲にしてスピードレベルの上げたり、その逆もあったりと様々です。さらにHSMのようにスピードとセキュリティの適用性を犠牲にするものもあります。SGXとMPCのようにスピードとセキュリティのトレードオフを可能にし、メッセージが最初から最後まで安全に保たれるような深い技術を追加することを可能とするように、様々な技術を組み合わせることが必要になってきます(例えば単一ノードのコンピュテーションの問題を減らすためにゼロ知識証明を使用すること、そしてデータがノード上でプライベートになっていることを確認すること)。その後、やっと私たちは有意義なプライバシーを達成することができます。
追伸 本記事で取り扱われていないもの:
差分Privacy:もしコンピュテーションで情報が漏れた場合はどうすればよいでしょうか?
準同型暗号:もし私の敵対者が私のPrivacyを侵す方法を持たせたくない場合はどうすればよいでしょうか?
区別できない難読化:もしコンピュテーションの背後にある実際のアルゴリズムを秘密にしたい場合どうすればよいでしょうか?(また、目撃者の暗号化、(否認可能暗号化、そして他多くの技術)。